A common frustration we’ve encountered is the lack of adequate tooling around ontology and knowledge graph schema design. Many tools exist– some are overly complex, some are very expensive, and none allow one to work visually, collaboratively and in real time on a document with multiple concurrent users.
That is why two years ago we took half a dozen Capsenta engineers and set off to design and develop a solution. Our design principles were:
– Real World: Focus on solving problems that we encounter in the real world with our customers and users. – Understand our audience: We work with data geeks but also business and domain experts– our solution has to satisfy them both. – Minimal: Let’s not boil the ocean; be focused and practical. – Do not reinvent the wheel: A lot of great research and scientific results exist that should be leveraged.
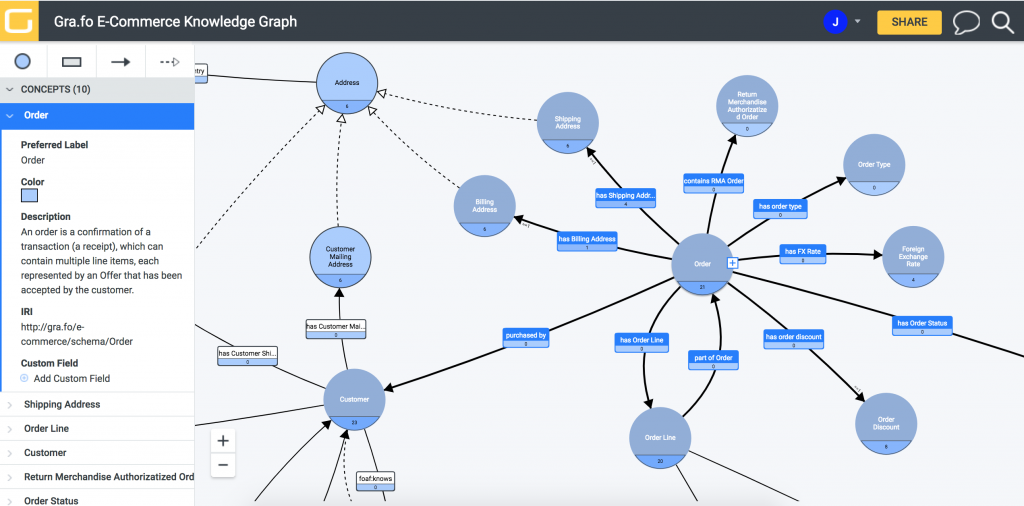
With that in mind, we are very pleased to announce the official launch of Gra.fo, a visual, collaborative, and real-time ontology and knowledge graph schema editor. It is the only editor where you can:
– Visually design your schema by dragging and dropping Concepts, Attributes, Relationships and Specializations– what we lovingly refer to as C/A/R/S. – Share your document with other users and grant view-only, commenting, or editing permissions. – Collaborate in real-time with multiple users. – Comment on individual C/A/R/S with other users. – Search for C/A/R/S. – Track document history, name a version and restore to any previous version.
After two years of stealth mode, we officially launched Gra.fo last week at the 17th International Semantic Web Conference (ISWC2018) in Monterey. The reception was universally positive. It was also very cool to demo Gra.fo to Sir Tim Berners-Lee!
Demoing Gra.fo to Sir Tim Berners LeeDiscussions with Sir Tim Berners-Lee on Gra.fo and Solid.
Gra.fo is currently the only visual, collaborative, and real-time ontology and knowledge graph schema editor in existence. But that’s not good enough for us. We want to be the best knowledge graph editor, period! Toward that end we are actively working on several new features with more to come:
– Git: Commit and push your document to Git. – Import Mapping: View R2RML mappings within Gra.fo. – API: Access and build knowledge graphs programmatically.
Please check it out athttps://gra.fo/. We offer one month gratis at the Team level so feel free to try out all that Gra.fo offers. Serving the community is important to us so please let us know what you need!
I went to this seminar with the following agenda: 1) share my new research interest on studying social-technical phenomena of data integration and see what others think, 2) learn what others think are the hard scientific challenges with Knowledge Graphs and most importantly 3) understand what is the big AHA moment with Knowledge Graphs. After spending the last few days processing the entire week, I feel that I achieved all the goals of my agenda.
Given that I wear two hats, industry and academia, let me summarize my takeaways w.r.t these two hats
Knowlede Graph PrehistoryKnowledge Graphs 20 years ago
Throughout the week, there was a philosophical and political discussion about the definition. Some academics wanted to come up with a precise definition. Others wanted it to be loose. Academics will inevitably come up with different (conflicting) definitions (they already have) but given that industry uptake of Knowledge Graphs is already taking place, we shouldn’t do anything that hinder the current industry uptake. For example, we don’t want people searching for “Knowledge Graphs” and finding a bunch of papers, problems, etc instead of real world solutions (this is what happened with Semantic Web). A definition should be open and inclusive. A definition I liked from Aidan Hogan and Antoine Zimmermann was “as a graph of data with the intention to encode knowledge”
FAIR Data and Best Practices: I believe that the notion of Findable Accessible Interoperable Reusable (FAIR) is brilliant! This doesn’t apply just for life science or research data. Every enterprise should strive to have FAIR data. Within life science, Barend Mons is pushing that the best practice to implement FAIR data is to create Knowledge Graphs in RDF. I agree because you want to share and reuse vocabularies, have unique identifiers and this is the core of RDF. However, we are missing a set of Best Practices; not just on how to create FAIR data but how to create, manage, maintain Knowledge Graphs in general.
Wikidata: I enjoyed chatting with Lydia Pintscher and learning how Wikidata really works. It is an interesting mix of tech and community. For example, users can create classes and instances but cannot create properties. If they believe they need to do it, it has to go through a community process.
Knowledge Graphs in the real world: We have all been hearing about the popular ones gaining press recently (Google, Amazon, Uber, Airbnb, Thomson Reuters) but I started to hear about others that I wasn’t aware about such as Siemens, Elsevier, Zalando, ING, etc. We need to start compiling a list of them. It was also great to hear from Dezhao Song on how the Thomson Reuters Knowledge Graph was created (spoiler alert: it’s a typical NLP pipeline). For more info, check out their paper “Building and Querying an Enterprise Knowledge Graph“.
Research Hat
The first two days were spent on discussing interest that we had in common and the challenges. I believe there were a total of 15 discussions going on. The topics were on: NLP, Graph Analytics, ML, Decentralized Web, Reasoning and Semantics, Constrained Access, DBpedia/Wikidata, Human and Social Factors, Data Integration, Evolution, What is a KG, Best Practices and more. There will be an official report on all these discussions so stay tuned!
My AHA Moment: Tuesday evening at the wine cellar we had a late (late) night discussion and some of us believed that the discussion up to now were definitely interesting but could be considered the natural, incremental, next steps. There was a lack of boldness and thinking outside of the box. What are the true grand challenges? Our late night discussion helped drive the atmosphere on Wednesday in order to focus on being bold.
I was extremely lucky to participate in a group discussion on Wednesday with Piero Bonatti, Frank van Harmelen, Valentina Presutti, Heiko Paulheim, Maria Esther Vidal, Sarven Capadisli, Roberto Navigli and Gerald de Melo. We started asking ourselves a philosophical question: What is the object of our studies? This question sparked fascinating discussions. I felt like a philosopher because we were questioning what we, as scientist, were actually researching. We are making observations about which natural phenomena? We are devising theories about what object? I’m happy to say that we did come to a conclusion.
In my own words: Knowledge Representation & Reasoning and Knowledge Engineering are fields that study the object of knowledge. Data management is a field that studies the object of data. Each of these fields have had independently advances on understanding this object and how it scales (where scales means the typical Vs: volume, variety, etc). Furthermore, efforts to study the relationship between these objects can be traced back to 1960s. However, what we observe now is a new object: knowledge and data at scale. I would like to be bold and state that studying the phenomena of knowledge and data at scale is it’s own field in Computer Science. Knowledge Graphs are a manifestation of this phenomena.
This was my AHA moment. After we shared this with the rest of the group, it sparked a lot of discussion, including the political and philosophical aspects of defining a Knowledge Graph.
Human and Social factors: Succinctly, my current research interest is in researching the socio-technical phenomena the occurs in data integration. With my industry hat on, I get to work with large enterprises on data integration. Throughout this work I observe the work we do with my research lenses and observe situations (phenomena) that I do not know how to deal with. For example, creating mappings is a not a problem that can be addressed easily with a technical/software solution. Schemas are extremely large and complex and you need specific knowledge (i.e. legal, business) that only specific users know, and they may not even agree. I had many interesting discussions with Valentina Pressutti, Paul Groth, Marta Sabou, Elena Simperl and I’m glad to realize that my research interest has merit and is shared with others. There is a lot of work to be done, specially because we, as computer scientist, need to interact with other communities such as cognitive science, HCI, etc. I’m very excited about this topic because it gets my out of my comfort zone.
Multilinguality: I have never followed this topic so it was great to learn about it. We were lucky to have Roberto Navigli part of the crew. I understood the true challenge of multilinguality of knowledge graphs when Roberto talked about the cultural aspects. For example, how do you define Ikigai in a Knowledge Graph and how do you link it to another entities?
Evolution: how do you represent evolutions of a Knowledge Graph? How do you reason with the evolutions?
I wrote this report without looking at Eva Blomqvist ’s and Paul Groth’s trip reports. I didn’t want to bias mine. Now I can read them.
A comment from Frank: It shouldn’t be called Computer Science. It should be called Computing Science because it’s a science that studies the phenomena of computing (not computers because that is the tool), the same way Astronomers don’t study telescopes, they use them as a tool.
I spent an extra day at Dagstuhl. It was nice to relax and reflect on the week. Additionally I spent almost 4 hours in the library and found a lot of gems: First volumes of JACM and a lot of cool bookssigned by the authors, including Edsger W. Dijkstra. I also found the book of my PhD dissertation in the library
What an amazing feeling to find the book of my PhD dissertation at the @dagstuhl Library. Also found the proceedings of ISWC 2017 where I appear as an editor.
This is a community with amazing scientist but also amazing musicians! We were lucky that Dagstuhl has a music room with a grand piano and guitars. Can’t wait for the ISWC Jam Session
Scientist investigate to understand natural phenomena, find answers to unsolved questions, in order to ultimately expand the knowledge of mankind. Yes this sounds cliche, but it’s true.
We should remember that science is a social process. It is paramount for scientist to be social and communicate with peers in order to share their ideas, hypothesis, results and receive critical feedback from others. This communication, historically and still today, is done written (papers) and orally (talks and conversations at conferences).
I can only provide my opinion from a computer science point of view, and my impression is that there is a tremendous focus today on reviewing, publications, conferences and citation counts.
I think we are forgetting the big picture: reviewing, publications, conferences are a means to an end. It is the means of communicating in order to achieve the end of understanding something that we do not understand today.
Some ideas/comments (inspired after a conversation with Wolfgang Lehner when I visited TU Dresden and talking to other colleagues in different sciences)
Papers published in top tier conference proceedings have a lot of weight in Computer Science. Fellow colleagues in other scientific fields find it amusing when we get excited about a conference publication because in most (all?) areas of science, journal papers are what counts. I know that the excuse is that CS moves so quickly and journal reviews take too long. So this is what we have to change. Therefore …
Conference submissions should be extended abstracts. Reviewing for these extended abstracts should be light. That means that we have less work as reviewers.
All accepted abstracts are presented as posters. The goal is to foster discussion, right?!We should have longer poster sessions everyday so everybody can have a chance to present and also see what others are doing. For example, recently, I received an email from a colleague who sent me a draft paper which was partly inspired by our discussion that we had in SIGMOD 2017. I didn’t even have a poster at the conference, it was just a conversation we had on our way to the gala dinner. We need to have more outlets for these types of conversations.
Journal papers get invited for longer presentations. ISWC and WWW (now TheWebConf) has been doing this for a couple of years now (and I’m sure other conferences too). All conferences should be doing this!
During the conference presentations, we should spend more time on discussion in addition to giving just talks, and having the session chair asking a question at the end because everybody is looking at their laptop. One idea is to create panels by grouping scientists who are working on the same topic. This is common in social science conferences.
We should publish in venues that don’t limit you on a fixed page limit (i.e. journals). Have something to say. Say it. Finish when you are done saying it (and give it a good title… this is advice that I heard from Manuela Veloso.)
– Research on a deadline is either engineering or not really research. Therefore, we should not focus on fixed yearly deadlines; you should be able to submit whenever you want. Submit when your work is actually DONE! Not when the conference deadline tells you. That way you can stop running experiments last minute (btw if you do that, your research is not done and not ready to be shared, IMO). I think the PVLDB model is fantastic and should be widely adopted in CS. I know that the typical excuse is that we need deadlines. BS! If you can’t manage your own time, then you have a bigger problem.
If conferences submissions are just extended abstracts, then we can focus our reviewing efforts on substantial papers.
At AMW2018, Paolo Guagliardo presented somebody else’s paper. He read the paper and did the best presentation possible which I’m sure will become a memorable presentation. Talking later to Hung Ngo and Paolo, we thought that it would be incredibly interesting to have a fellow colleague present your work. This could either be a PC member who reviewed your paper, or another colleague who shares the same interest and is willing to read the paper and present it. Imagine having somebody else being critical about your paper and present it to others. A bit risky for sure, but why not try this out with people who are willing to swap. Maybe at your next conference, you can surprise the audience with this approach. I know I would love to do it.
I acknowledge that my suggestion will never work due to the larger “system”. CS academics get evaluated by universities and funding agencies through the quantity of publications and citation counts. That has to be reformed. Easier said than done of course. If that continues to be the norm of evaluation, we are going to stay in the same place and keep adding bandaid after bandaid and hearing the same rants without any progressive change. Scientist high up in the ranks who have power are the ones that can make the change. I truly believe we need a change.
This week, the 12th Alberto Mendelzon Workshop on Foundations of Data Management (AMW2018) takes place in Cali, Colombia. I have been coming to AMW since Cartagena, Colombia in 2014 and it has always been a fabulous event: strong scientific program, fun people and great organizations. I’m incredibly humbled, honored and excited to be the General Chair of AMW2018. It is a tremendous distinction to have the opportunity to be part of this distinguished event and share with my database friends and colleagues in Cali, Colombia, which is a place I call home.
AMW2018 has a fantastic program this week, and it is all thanks to the PC Chairs, Dan Olteanu (University of Oxford) and Barbara Poblete (University of Chile), the School Chairs, Jarek Szlichta (University of Ontario) and Domagoj Vrgoč (PUC Chile) and the authors of the 29 papers that will be presented.
The AMW School takes place during the first two days of the week with four tutorials:
– Denis Parra (PUC Chile): A Tutorial on Information Visualization and Visual Analytics
– Miriam Fernandez (Open University): Introduction to Mining Social Media Data
– Martin Ugarte (Free University of Brussels): Understanding the Bitcoin Protocol
– Fei Chiang (McMaster University): Introduction to Data Quality
– Miriam Fernandez (Open University) on AI for policing
– Hung Ngo (RelationalAI Inc) on worst-case optimal join algorithms
– Pablo Barcelo (University of Chile) on on reverse engineering problems for database query languages
– Vanessa Murdock (Amazon) on on large-scale analysis of user engagement
I am extremely grateful to the sponsors and the local organizing committee. We received generous support from VLDB Endowment and Cafeto Software. Thanks to their support, we are able to fund 25 students! The local organizers, Andres Castillo (Universidad del Valle) and Maria Constanza Pabon (Pontificia Universidad Javeriana Cali) have been a tremendous support on making this event happen.
Last but not least, given that AMW2018 is taking place in Cali, Colombia, this organization has become a family affair. My parents, and specially my mother, have been right by my side to make sure AMW2018 is a success. This event is taking place thanks to my mother! Gracias mami!
Hopefully you are now tempted to come to the next AMW, which will be somewhere in Latin America!
I recently attend the 1st US Semantics Technology Symposium. I quickly published my trip report because I wanted to get it out asap, otherwise I would never get it out (procrastination!). It’s been a week since my trip report and I can’t stop thinking about this event. After a week of reflection, I realized that there is a big picture that did not come across my trip report: THE US2TS WAS A VERY BIG DEAL!
Why? Three reasons:
1) There is a thriving U.S. community interested in semantic technologies
2) We are not alone! We have support!
3) Time is right for semantic technologies
Let me drill through each one these points.
1) There is a thriving US community interested in semantic technologies
Before the event, I asked myself: what does success look like personally and for the wider community after this event? I didn’t know what to expect and honestly, I had low expectations. I was treating this event as a social gathering with friends and colleagues that I hadn’t seen in a while.
It was much more than a social gathering. I realized that there was a thriving US community interested in semantic technologies, outside of the usual suspects (academics such as USC/ISI, Stanford, RPI, Wright State, UCSB and industry such as IBM and Franz). At the first coffee break, I told Pascal “I didn’t know there were all these peoples in the US interested in semantic technologies!”. Apparently many people shared the same comment with Pascal. US2TS was the first step, in my opinion, to unify an existing community that was not connected in the US.
I’ve known about the semantic work that Inovex and GE Research have been doing. I was very glad to see them coming to an event like this and publicizing to the wider community about what they are doing.
Very exciting to meet new people and see what they are doing coming from places such as Maine, U Idaho, UNC, Cornell, UC Davis, Pitt, Duke, UGA, UTEP, Oregon, Bosch, NIST, US AF, USGS, Independent Consultants,
Additionally, very exciting to see the different applications domains. Life Science has always been prominent. I learned about the complexity of geospatial and humanities data. I’m sure there are many more similar complex use cases out there.
2) We are not alone! We have support!
The US government has been funding work in semantic technologies through different agencies such NSF, DARPA and NIH. Chaitan Baru, Senior Advisor for Data Science at the National Science Foundation had a clear message. NSF thinks of semantic technologies as a central component of one of its Ten Big Ideas: Harnessing the Data Revolution:
How do we harness the data revolution? Chaitan and others have been working through NITRD to promote an Open Knowledge Network that will be built by many contributors and offer content and services for the research community and for industry. I am convinced that an Open Knowledge Network is key component to harness the data revolution! (More on Open Knowledge Network below.)
Basically, NSF is dangling a $60 million carrot in front of the entire US Semantic Technologies community.
Chaitan’s slides will be made available soon through the US2TS web site.
3) Time is right for Semantic Technologies
Semantic Technologies work! They solve problems that require integrating data from heterogeneous sources where having a clear understanding of the meaning of the data is crucial. Craig Knoblock’s keynote described how to create semantic driven applications from end to end in different application domains. Semantic technologies are key to address these problems.
One of the themes was that we need better tools. Existing tools are made for citizens of the semantic city. Nevertheless, we know that the technology works. I argue that it is the right opportunity to learn from our experiences and improve our toolkits. There may not be science in this effort and that’s fine. I think that is a perfect fit for industry and startups. I really enjoyed talking to Varish and learning how he is pushing for GE Research to open source and disseminate the tools they are creating. Same for Inovex. One of our goals at Capsenta is to bridge the chasm between the semantic and non-semantic cities by creating tools and methodologies. Tools don’t have to come just from academia. It’s clear to me that the time is right industry to work on tools.
1) The thirst for semantics are growing: We are seeing the interest in other areas of Computer Science, namely, Machine Learning/Data Science (slide 3), Natural Language Processing (slide 4), Image Processing (slide 5), Big Data (slide 6) and Industry through Knowledge Graphs (slide 7). If the thirst for semantics is growing, the question is, how are we quenching that thirst? We are seeing Deep Learning workshops at semantic web conferences. It’s time that we do it the other way: semantic/knowledge graphs papers and workshops at Deep Learning conferences.
2) Supercomputing analogy: In 1982, Peter Lax chaired a report on “Large Scale Computing in Science and Engineering”. During that time, supercomputing had major investments by other countries, dominated by large industry players, limited access to academia and lack of training. The report recommend NSF to invest in Supercomputing. The result was the National Science Foundation Network (NSFNET) and the Supercomputing centers that exist today. This seems like an analogous situation when it comes to semantics and knowledge graphs: major investments by other countries (Europe), dominated by large industry players (Google, etc), limited access to academia (not mainstream in other areas of CS) and lack of training (we need to improve the tools). I found this analogy brilliant!
3) We need an Open Knowledge Network: As you can imagine, to continue the analogy, we need to create a data and engineering infrastructure around knowledge, similar to the Supercomputing centers. An Open Knowledge Network would be supported by centers at universities, support research and content creation by the broader community, be always accessible and reliable to academia, industry, and anyone, and enable new scientific discoveries and new commercial applications. For this, we need to think of semantic/knowledge graphs as reliable infrastructure, train the next generation of researchers, and think of the Open Knowledge Network as a valuable resource worth of collective investment.
Do yourself a favor and take a look at the Yolanda’s slides.
Conclusion
This is perfect timing. We have a thriving semantics technology community in the US. Semantic technologies work: we are seeing a thirst for semantics and interest from different areas of computer science. Finally, the NSF has a budget and is eager to support the US Semantic technologies community.
I attended the 1st U.S. Semantic Technologies Symposium (#US2TS), hosted by Wright State University in Dayton, Ohio on March 1-2, 2018. The goal of this meeting was to bring together the U.S. community interested in Semantic Technologies. I was extremely happy to see 120 people get together in Dayton, Ohio to discuss semantics for 2 days. I’m glad to see such a vibrant community in the U.S. … and not just academics. Actually, I would say that academics were the minorities. I saw a lot of familiar faces and met a lot of people from different areas.
The program was organized around the following topics: Cross Cutting Technologies, Publishing and Retrieving, Space and Time and Life Sciences. Each topic had a set of panelists. Each panelist gave a 10 minute talk. There was plenty of time for discussion and a break out session. It was a very lively. The program can be found here: http://us2ts.org/posts/program/
I gave a 10 min version of my talk “Integrating Relational Databases with the Semantic Web: a journey between two cities“. The takeaway message: in order to use semantic technologies to address the data challenges of business intelligence and data integrate, we need to fulfill the role of the Knowledge Engineer and empowered them with new tools and methodologies. Looks like I did a good job at it and it was well received 😃
Complexity and Usability of ontologies was a topic throughout the two days. Hallway talk is that light semantics is enough (happily surprised to hear this). However, Life Science and Spatial domain need heavyweight semantics (more below). CIDOC-CRM is the ontology used in the museum domain. Apparently very complicated. A lot of people don’t like it but they have to use it.
Linked Open USABLE Data (LOUD): We need to find a balance between usable and complexity.
I was part of a breakout session on ontologies and reuse. I really appreciated Peter Fox’s comment on ontologies (paraphrasing): there are three sides that we need to take into account 1) expressivity, 2) maintainability and 3) evolvability
Tools Tools TOOLS: we need better tools. That was another theme of the meeting. There seemed to be an agreement with my claim that the existing tools are made for the semantic city.
JSON-LD came up a lot. People love it.
Application Areas of Semantics
As expected, Life science was present at this meeting. Melissa Haendel from Oregon Health & Science University showed some really cool results that were possible thanks to semantics. Chris Mungall from Lawrence Berkeley National Laboratory gave an overview of the Gene Ontology.
I need to check out perio.do: “A gazetteer of period definitions for linking and visualizing data“. One of the project leads is a fellow longhorn, Prof. Adam Rabinowitz. I want to meet him!
Meeting people
Great chatting with Varish Mulwad from GE Research and learning about all the semantic work that is going on at GE Research. Need to check out Semtk (Semantics Toolkit ) and these papers: .
Excellent presentation by @yolandagil making the case for the Open Knowledge Network and comparing Semantic Technologies today with Supercomputing in the 1980s. Additionally a clear roadmap resulting from this #us2ts meeting pic.twitter.com/DEQ5P5MrPT
This is an event that was missing in the U.S. I’m glad that it was organized (Fantastic job Pascal and Krzysztof!). Looking forward to this event next year!
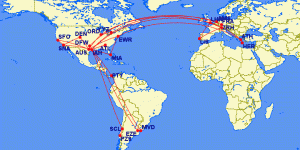
I travelled a lot in 2017. The most I have ever traveled before. I flew 163,195 miles which is equivalent to 6.6x around Earth. I was on 114 flights. I spent almost 400 hours (~16 days) on a plane. I visited 17 countries: Austria, Argentina, Canada, Chile, Colombia, France, Germany, Greece, Guatemala, India, Mexico, Netherlands, Portugal, Spain, Switzerland, UK, Uruguay. I was in Austin for 164 days (my home), 61 days in Europe, 28 days in Colombia and 16 days in India. I slept 30 nights at a Marriott, 27 nights at an Airbnb and 13 nights on a plane.
Given all this travel, I asked myself: what was my most memorable event of 2017?
In July, I gave a lecture at the 2017 Reasoning Web Summer School and attended the RuleML+RR 2017 Conference. The conference dinner was at the Royal Society of London. Bob Kowalski gave the dinner speech titled “Logic and AI – The Last 50 Years”. It was the 50th anniversary of when he started his PhD, which gave the rise to logic programming. Additionally, by pure coincidence I sat next to Keith Clark. The combination of sitting next to Keith Clark and listening to Bob Kowalski’s is what made this my most memorable event of 2017
Why?
Early during my PhD, my advisor, Dan Miranker, encouraged me to read about the 5th Generation Japanese Project (if you don’t know what this is, go look it up NOW!) During my research, in order to trace back the relationship between Logic and Data, I encountered the landmark 1977 Workshop of Logic and Data Bases organized by Herve Gallaire, Jack Minker and Jean-Marie Nicolas. That workshop is where Ray Reiter presented his paper on Closed World Assumption, Bob Kowalski presented his paper on Logic for Data Description and Keith Clark presented his paper on Negation as Failure. I even have a copy of the proceedings:
Every time I give a talk on this topic, I reference that 1977 workshop to provide historical context of where we are today. See slide 4:
1) What is the relationship between declarative and imperative representation of knowledge?
2) What is the relationship between different types of rules?
As you can imagine, sitting next to Keith Clark, listening Bob Kowalski’s talk and having the opportunity to chat with them is what made this a truly amazing evening.
With Bob Kowalski
With Keith Clark
What an evening! An evening I will never forget! Thank you Bob and Keith!
Oh, I even saw Alan Turing’s Certificate of a Candidate for Election into the Royal Society.
First of all, I’m honored to be part of the Organizing Committee as a chair of the In-Use Track, together with Philippe Cudré-Mauroux. Jeff Heflin was the General Chair and a fantastic leader. The conference was impeccable thanks to the AMAZING local organization. Axel Polleres and Elmar Kiesling did an incredible job. I truly enjoyed every step of the process to help organize ISWC 2017. I am really looking forward to ISWC 2018 in Monterey, CA and ISWC 2019 in Auckland, New Zealand!
Btw, if you have the chance to see Frank give a talk… it’s a must! He is one of the best speakers in academia that I have ever seen. I wish I could present like him!
I attended most of VOILA!2017 Workshop. The highlight of the event was the demos. Around 20.
* Next version of VOWL is addressing a lot of needs.
* Check out ViziQuer. It looks cool but I’m skeptical about how usable it is.
* Great to see interest on UIs for generating R2RML mappings but they haven’t been tested yet with real world scenarios. Long ways to go here.
* I need to check out the Linked Data Reactor
* Treevis.net, interesting resource. Need to check it out.
* The extensible Semantic Web Browser
* user, user, user: everybody mentions users but usually the “user” is not defined. Who exactly is your user?
Welcome ceremony was in the Vienna Rathaus. Beautiful place. We were so lucky.
During the welcome ceremony, we had reencounter of 5 alumni from the 2008 Summer School on Ontological Engineering and Semantic Web: Laura Drăgan, Tara Raafat, Maria Maleshkova, Anna Lisa Gentile and myself with John Domingue and Enrico Motta who were the organizers. We have gone a long ways!
Industry and In use: If I’m not wrong, approximately 25% of attendees of ISWC were from industry and government (more specifically not from academia). All the industry talk were on Monday. Great to see the room full all of the time. We are definitely seeing more use of semantic technologies. However, my observation is that this is mainly government and research/innovation folks are very large companies. It is not yet replacing the status quo. Additionally, a lot of complaints about the lack of maturity of tools, specially open source tools. I’m not surprised.
Ontology engineering seems to be popular (or it never stopped?). Deborah McGuinness‘ keynote showed real world projects in health care where ontologies play a central and vital role. Takeaway message: it takes a village.
It seems to me that we have had the following evolution in the past decade: first focus on hard core theoretical ontologies (DL and the like), second focus has been more on the data side (Linked Data), third focus (now) is about “little semantics goes a long way”. Jim Hendler has always been right (see my comments below on Jamie Taylor’s keynote).
Is this the year of the Knowledge graph? Are Knowledge Graphs becoming Mainstream? Thomson Reuters announced (by coincidence?) their Knowledge Graph while ISWC was going on. There was no formal announcement during the conference.
I presented a poster on the Ontology and Mapping Engineering Methodology that we have been using at Capsenta in order to apply semantic web technologies to address data integration and business intelligence pain points. THANK YOU THANK YOU THANK YOU for all the feedback that I received during the poster session and hallway conversations. This is the reason why you go to a conference! Special shoutout to Enrico Franconi and Frank van Harmelen. Conversations with you were extremely insightful.
Jamie Taylor, the former Minister of Information at Freebase (and the person who has had one of the coolest titles) and who now manages the Schema Team for Google’s Knowledge Graph gave the third keynote, which btw, was exactly what you expect for a keynote. Thanks Jamie for such an awesome talk!
His message was very clear: we need actionable and executable Ontologies/Knowledge Graphs. What does this actually mean? The example he gave was the following: in the Google KG, they have assertions that Polio and the Vaccine for Polio, but no where it is asserted that the Vaccine for Polio prevents Polio. This goes into adding common sense knowledge (think about Cyc). I think it would be fair to say that the lessons learned reported by Jamie were a bit “duh”/“told you so” to this community. My observation is that the giant Google, at the end, is doing what the Semantic Web community has been working on for over a decade. This is good! It was very nice to see the evolution of the Knowledge Graph at Google and insightful to see the practical role that semantics take place. Pascal Hitzler quickly wrote up his take away from Jamie’s keynote.
This paper presents foundational work towards understanding what are Linked Data Fragments (LDF) and the relationship between different types of LDF. From a more general point of view, this work helps to formalize the relationship between a Client-Server architecture. Hence it’s applicability is not just within the Semantic Web. This is a beautiful example of how theory and practice can be bridged. Additionally, the presentation was simply brilliant. Jorge Perez has the capability of taking the most complicated concepts and presenting them in a way which is understandable and enjoyable to the audience. I can’t wait to see this presentation on video lectures. When it is published, this is a must see on how to present a paper at a conference. I wish I could present like Jorge!
Check the slides of my talk about Linked Data Fragment Machines at https://t.co/G5m9JDtWs2 And come to see the talk, next session! #iswc2017
Daniel Garijo presented his WIDOCO tool. If you work with ontologies, you really need to use this tool which basically is an outsource for the documentation of the ontology. He also received the Best Paper Award for the Resource track. Well deserved!
The Job Fair was a great addition. Looking forward to seeing its evolution in the upcoming ISWC.
I really enjoyed being part of the mentoring session. It’s great to hear students about what worries them and provide some advice. We discussed paper publishing process, academia vs industry, US vs Europe, dealing with loneliness, and many more topics. Please reach out if you have any questions!
and without further ado, here is 1+ hour video of the Jam Session, a large group of Semantic Web Computer Scientist PhDs jamming, after just 3 hours of practice. I think this is the definition of epic! Enjoy!
In May 2017, Escape ATX shared a deal for Austin to Guatemala for $300! I immediately jumped on it. Last weekend I visited Guatemala, specifically Antigua. This small town used to be the capital of the Kingdom of Guatemala (which included most of Central America) in the 1700s and is now UNESCO World Heritage Site. After the peace was signed in the mid 90s, Antigua started to boom with a lot of tourist but continued to maintain it’s small town appeal.
For me, the best way to summarize Antigua is the following: imagine a typical pueblo in Latin America (in Colombia think Villa de Leyva o Salento) mixed with the cosmopolitan vibe of Austin. Cobble stone roads, colonial style housing, park in the middle of the town with the cathedral in front, with high end luxury restaurants, bars with pub food, local craft beer, hole in the wall bars.
I observed three types of foreigners:
1) tourists
2) short term: foreigners coming for volunteering or “figuring what I want to do with life” who come for months and may end up staying for a year or two
3) resident immigrants: foreigners who have been living in Antigua for many years and are owners of a bar or restaurant
Antigua is a bubble within Guatemala. It is not cheap (same prices as in Austin). But it has a charm, a “no sé que” that wants me to come back. I can see myself going back and working from Antigua for a week or two (who would be interested?)
These are some of the places that I visited which I recommend:
Chermol: Argentinean restaurant. Wide variety of local craft beers
Cafe No Se: The famous Cafe No Se. It’s been featured in NY Time’s “What to do in 36 hours in Antigua Guatemala”. It’s a hole in the wall, mostly full of foreigners. In the back they have the a mescal bar where they only serve Illegal mescal and beer. Music is blues/soul which reminds me of Thursday night at Barberella in Austin
This has been a summer of Computer Science, Research, Semantic Web, Databases, Graphs and a lot of travel! In these past 4 months, I visited 10 countries and traveled over 72,000 miles; equivalent to going around the world 3 times. Whew! This is the summary of my summer travel.
Montevideo
I attended the 11th Alberto Mendelezon Workshop on Foundations of Data Management. AMW is a scientific event with with a heavy attendance from database theory researchers. The hallway discussions are very insightful. I was the organizer of the Summer School and a presented a short paper titled “Ontology Based Data Access: Where do the Ontologies and Mappings come from?”I had a lot of enlightening conversations with Luna Dong from Amazon (working on creating the Product Knowledge Graph. Semantic web is involved), Julia Stoyanovich who gave a real thought provoking tutorial on Data Responsibility (we should all pay attention to this), Leonid Libkin (Nulls in databases are still an issue). I was thrilled to finally meet Dan Suciu, James Shanahan, Jan Van den Bussche among many other database gurus. It’s always a pleasure to hang out with the chilean database “mafia”: Marcelo Arenas, Pablo Barcelo, Leo Bertossi, Claudio Gutierrez, Aidan Hogan et al. Congrats to the local team for organizing a wonderful event, specially to Mariano Consens!
Buenos Aires
I flew into Montevideo and I was flying out from Buenos Aires. I got to spend a day and a half in this great city. I truly enjoyed it. I will have to come back! Blog post about my 36 hour visit to Buenos Aires will come soon.
San Francisco
I attended Graph Day where I had two talks “Do I need a Graph Database? If so, what kind?” and “Graph Query Language Task Force Update from LDBC”. My takeaways:
– AWS is figuring out what to do with Graphs
– Uber is creating a Knowledge Graph
– Stardog, was the only RDF graph database company there. They are growing and very direct with their material: if you are doing data integration, you should be using RDF.
– Multi-model databases are growing: Datastaxs, ArangoDB, OrientDB, and Microsoft’s latest release of CosmosDB
– New Graph databases: JanusGraph, Dgraph, AgensGraph
– openCypher is really pushing hard to be THE property graph query language standard
We had extensive discussions on the state of the art in Federated Query Processing from the traditional Relational Databases and Semantic Web perspectives. The goal was to understand the limitations of current approaches in considering ontological knowledge during federated query processing. Federated Semantic Data Management (FSDM) can be summarized in one sentence: Being able to do 1) reasoning/inferencing over 2) unbounded/unknown sources. A couple interesting open challenges to highlight are the following:
1) Unbounded sources: In traditional federated data management, the number of sources is fixed. In FSDM, the number of sources may not be known. Therefore the source selection problem is harder.
2) Correctness: A relaxed version of correctness may need to be considered, a tradeoff between soundness/completeness and precision/recall.
3) Access control: This is still an open challenge even in traditional federated data management.
Switzerland
This is my third home. I try to swing by Zurich once a year. I spent a weekend at Bodensee and visited for the first time Säntis. I had the opportunity to visited Philippe Cudré-Mauroux at the University of Fribourg. We are the ISWC 2017 In-Use PC Chairs, so we had a face-to-face PC meeting. I also gave my talk “Integrating Relational Databases with the Semantic Web: past, present and future” for the first time. This talk is an 1 hour version of my upcoming lecture at the Reasoning Web Summer School in London.
Lisbon
What’s the best way to get from Zurich to London? Stopping for an entire day in Lisbon of course! Specially when you pay for the ticket with miles and $10USD. This was my first time in Lisbon. I arrived early morning, spent 6 hours walking around this amazing city. I also had the chance to have lunch with Sofia Pinto overlooking Lisbon and discuss ontology engineering! One of the best day layovers I have ever had. I have to come back. Blog post on the visit soon.
Client work took my all the way to Toronto. First time in Canada! So if it’s hot in Texas, might as well try to spend time in a cooler place. This is a great weekend getaway destination (in the summer): fantastic views, food and beer. I also had the chance to meet up with Mariano Consens and get a tour of the University of Toronto.
Chile
The Graph Query Language task force from the Linked Data Benchmark Council (LDBC) organized a face-to-face week meeting in Santiago, Chile to work on the proposal for a closed graph query languages where paths are first class citizens. A full week of hard work (we also had fun). I took advantage of this visit to visit my UT friends Lindsey Carte, Alvaro Quezada-Hofflinger and Marcelo Somos, professors at the Universidad de La Frontera in Temuco. I gave a talk in spanish “Integrating Data using the Semantic Web: The Constitute Use Case”. It is enjoyable challenge to give talks to non-computer scientists.
Miami
Back in February I found a Austin-Miami roundtrip ticket for $110. So why not! We discovered the Barrel of the Monks brewery in Boca Raton. This is a must if you are in that area and you like belgium beers!
Greece
I was invited to attend the STI Summit in Crete. My first time in Crete, and in Greece (I have never attended ESWC which is usually in Crete). Very intense couple of days talking about the future of Semantic Web research. Afterwards I visited Irini Fundulaki at FORTH and Giorgos Stamou at the National Technical University of Athens where I gave my talk on Integrating Relational Databases with the Semantic Web. I was very impressed with all the work on mappings that has been done in both of these groups. In both cases, the one hour talk turned into hours and hours of fruitful discussions. On my flight to Athens I met a fellow travel geek:72hrJetsettergirl. The next day, we randomly bumped into each other at the Acropolis. The sweet coincidences of life!
Atlanta
I attended the ACM Richard Tapia Celebration of Diversity in Computing. I have been attending this conference for 10 years, since I was a senior in college, all throughout my graduate studies and now has a PhD. This year, I was the Workshop and Panel Chair. I had the chance to moderated a panel “From Research to Startup” with Rachel Miller from Asana (from theory/crypto research to startup), Kunle Olukotun, (Stanford professor and founder of multiple startups) and Andy Konwinski (PhD from UC Berkley and co-founder Databricks). I also was on another entrepreneur panel with Ayana Howard (Professor at Georgia Tech and founder of Zyrobotics) and Jamika Burge. Both panels had a mix of undergrad, grad students and even faculty interested in learning and entrepreneur experiences. We definitely had an amazing group of panelists. Kemafor Anyanwu Ogan invited me to be on her panel of Data Management for IoT. One of the highlights of the conference is to meet with former and new members of Hispanics in Computing including Manuel Pérez Quiñones (congrats on the Richard A. Tapia Achievement Award for Scientific Scholarship, Civic Science and Diversifying Computing!) and Dan Garcia. We missed you Jose Morales and Patti Ordonez!
Netherlands
I’m writing this post on my way back from Amsterdam. I had the opportunity to meet up with Peter Boncz and talk about Graph Query Language use cases. I also gave my talk “Integrating Relational Databases with the Semantic Web” at the VU Weekly Artificial Intelligence meeting. Great crowd and a lot of great questions. Nice seeing Frank van Harmelen and Javier Fernandez.
The summer is well over. Fall is already in full force in Europe. But it is still feels like summer in Texas.