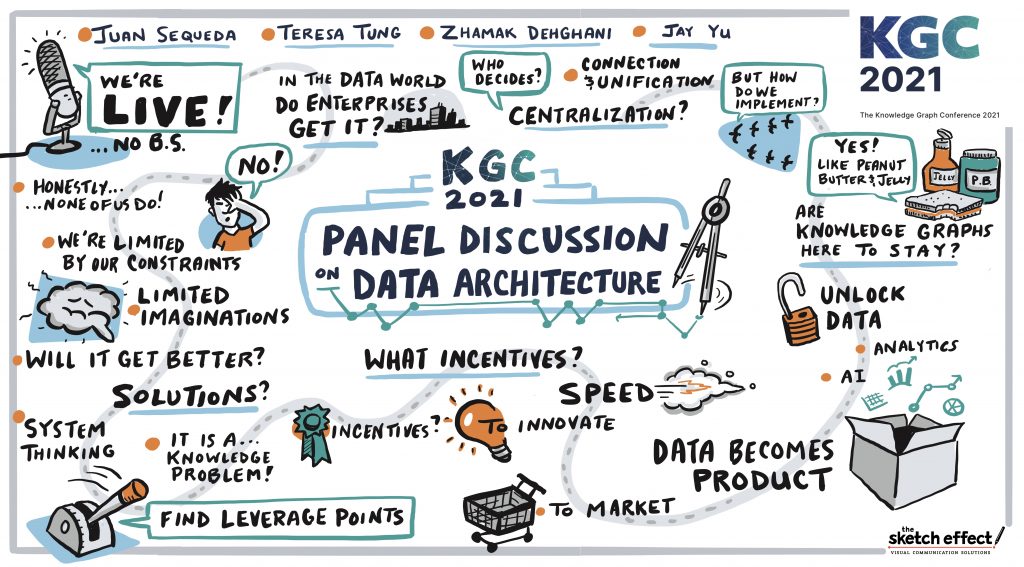
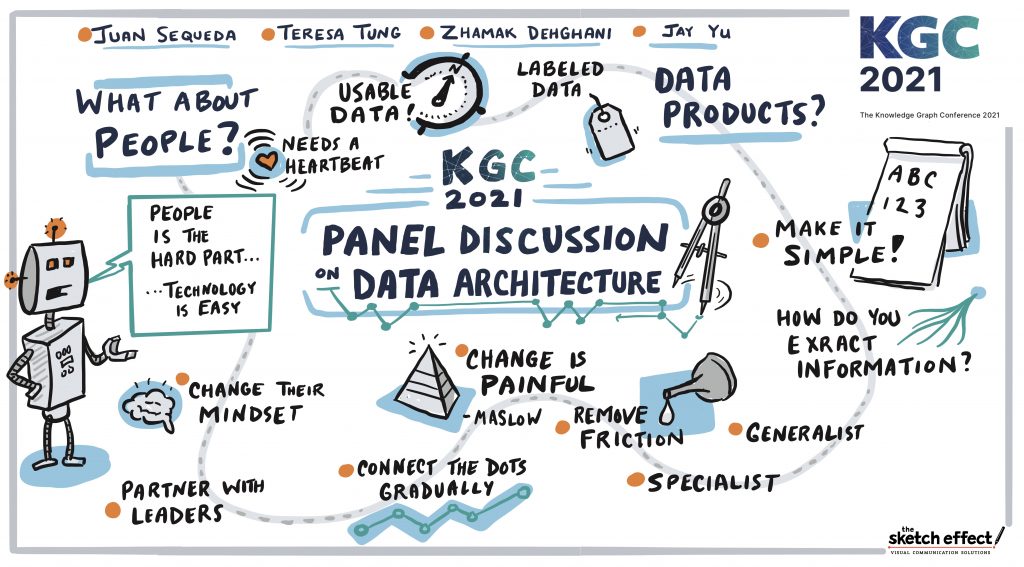
I had the honor to moderate the Data Architecture panel at the 2021 Knowledge Graph Conference. The panelist were:
– Zhamak Dehghani, Director of Emerging Technologies at ThoughtWorks and the founder of Data Mesh concept – Teresa Tung, Chief Technologist of Accenture’s Cloud First group – Jay Yu, Distinguished Architect and Director, Enterprise Architecture and Technology Futures Group at Intuit
This panel was special edition of the Catalog and Cocktails podcast that I host, an honest, no-bs, non-salesy conversation about enterprise data management. We will be releasing the panel as a podcast episode soon, so stay tuned!
Live depiction of the panel
In the meantime, these are my takeaways from the panel:
What are the incentives?
– Need to understand the incentives for every business unit. – Consider the common good of the whole, instead of individualism – Example of incentive: put OKRs and bonus on the shareability and growth of the users of your data products
Knowledge Graph and Data Mesh
– Knowledge Graph is an evolution of master data management. – Data Mesh is an evolution of data lake. – Knowledge Graph and Data Mesh complement each other. They need to go together. – However, we still need to figure out how to put them together.
Centralization vs Decentralization
This was the controversial part of the discussion. – Jay’s position is that the ultimate goal is to unified data and decentralized ownership of domain is a step in that direction. Zhamak and Teresa do not fully agree. – Intuit’s approach: There are things that should be fix (can’t change, i.e. address), flexible (ability to extend) and customize (if you need to hit the ground running) – Is the goal to unify data or have unifiable data? – Centralization and Decentralization: sides of the same coin – Centralize within a same line of business that is trying to solve the same problem. But can’t expect to follow all the new demands of data in the world.
People
– Need to have an answer to “what’s in for me?” question. See incentives takeaway. – Consider Maslow’s hierarchy of needs – Be bold, challenge the status quo – Follow the playbook on change management
Honest, no-bs: What is a Data Product?
– Native data products which are close to the raw data. Intelligent data products which are derived from the native data products – A data product is complete, clean, documented, with knowledge about the data, explanation on how people can use it, understand the freshness, lineage, useful – If you find something wrong with the data product, you need to have ways of providing feedback. – Data Products needs to have usability characteristics. – Data has a Heartbeat: it needs to be alive. The code keeps the data alive. Code and data need to be together. Otherwise it’s like the body separated from the soul. (Beautifully said Zhamak!)
Data Mesh was music to my ears because it centers enterprise data management around people and process instead of technology. That is the main message of my talk “The Socio-Technical Phenomena of Data Integration and Knowledge Graphs” (short version at the Stanford Knowledge Graph course, long version at UCSD). I’ve also been part of implementations, and known colleagues who have implemented approaches that I would consider Data Mesh.
In this post, I want to share my point of view on data mesh. Note, that these are my views and opinions and do not necessarily reflect the position of my employer, data.world.
The way we have been managing enterprise data basically hasn’t changed in the past 30 years. In my opinion, the fundamental problems of enterprise data management are:
1. We have defined success from a technical point of view: physically integrate data into a single location (warehouse/lake) is the end goal. In reality, success should also be defined from a social perspective: those who need to consume the data to answer business questions.
2. We do not treat data with the respect it deserves! We would never push software code to a master branch without comments, without tests, without peer review. But we do that all the time with data. Who is responsible for the data in your organization?
These problems have motivated my research and industry career. I was thrilled to discover Data Mesh and Zhamak Dehghani’s article because it clearly articulate a lot of the work that I have done before and given me a lot of ideas to think about.
Data mesh is NOT a technology. It is paradigm shift towards a distributed architecture that attempts to find an ideal balance between centralization and decentralization of metadata and data management.
The success is highly dependent of the culture (people, processes) within an organization, and not just the tools and technology, hence the paradigm shift. Data mesh is a step in changing the mindset of enterprise data management.
Important principles of data mesh
In my opinion, the two key principles of a data mesh are:
1. Treat data as a first class citizen: data as a product 2. Just how in databases you always want to push down filters, etc, why not push down the data back to the domain experts and owners.
Organization/Social/Culture
Let’s talk about organization/social/culture first. Technology after. I have experienced the ideal balance between centralization and decentralization of metadata and data management as follows:
Centralize the core business model (concepts and attributes). For example, the core model of an e-commerce company is simple: Order, Order Line, Product, Customers, Address. An Order has order date, currency, gross sales, net sales, etc. These core concepts and attributes should be defined by a centralized data council. They provide the definitions, the schema definitions (firstname vs first_name vs fname). It is CORE, which means that they do not boil the ocean. Per a past customer experience, when we started, the core model started out with 15 concepts and 40 attributes. 3 years later, it’s at 120 concepts and 500 attributes. Every concept and attribute has a reason for existence.
Decentralize the mapping of the application data to the core business model. This needs to be done by the owners of the data and applications because they are the ones who understand best what that data means.
“But everyone is going to have a different way of defining Customer!” Yes, and guess what… that’s fine! We need to be comfortable, and even encourage this friction. People will start to complain and this is exactly how we know what the differences are. This friction will eventually get boiled up to the centralized data council who can help sort things out. A typical result is that new concepts get added to the core business model. This friction helps prioritize the importance and usage of the data. Document this friction.
“My concept doesn’t exist in the core business model!” That’s fine! Create a new one. Document it. If people start using it and/or if there is friction, the centralized data council will find out and it will eventually become part of the core business mode.
If you are an application/data owner, and you don’t use the core business model, you are not being a good data citizen. People will complain. Therefore, you will be incentivized to make use of the core business model, and extend it when necessary.
People are at the center of the data mesh paradigm
We must have Data Product Managers. Just like we have product managers in software, we need to have product managers for data. Data Consumer to Data Product Manager: “is your data fit for my purpose?”. Data Product Manager to Data Consumer: “is your purpose fit for my data?”
We must have Knowledge Scientist: data scientist complain that they spend 80% of their time cleaning data. That is true, and in reality it is crucial knowledge work that needs to be done, understanding what actually is meant by “net sales of an order” and how is that physically calculated in the database. For example, the business core model states that the concept Order has an attribute netsales which is defined by the business as gross minus taxes minus discounts, However there is no netsales attribute in the application database. The mapping could be defined as a SQL query as SELECT ordered, sales - tax - discount as netsales FROM order
For largish organizations, business units will have their own data product managers and knowledge scientist.
Technology is part data mesh too
A data catalog is key to understand what data exists and document the friction. (Disclaimer: My employer is data.world, a data catalog vendor). Data catalogs are needed to catalog the as-is application-centric databases: the database systems that consists of thousands of tables and columns to understand what exists. This will be used by the data engineers and knowledge scientist to do their job to create the data products. Data catalogs will also be used to enable the discover and (re-)use of data products: each domain will create data products to satisfy business requirements. These data products need to discovered by other folks in the organization. Therefore, the data catalog will be used to catalog these data products so others can discover them.
Technologies such as data virtualization and data federation can be used to create the clean data views which can then be consumed by others. Hence, they can be used as implementations for a data mesh.
Knowledge Graphs is a modern manifestation of integrating knowledge and data at scale in the form of a graph. Therefore it is perfectly suited to support the data mesh paradigm. Furthermore, the RDF graph stack is ideal because data and schema are both first class citizens in the model. The core business models can be implemented as ontologies using OWL, and they can be mapped to databases using the R2RML mapping language, data can be queried in SPARQL in a centralized or federated manner. Even though the data is in the RDF graph model, it can be serialized in JSON. There is no schema language for property graphs (Disclaimer: My academic roots are in the semantic web and knowledge graph community, I’ve been part of W3C standards and I’m currently the chair of the Property Graph Schema Working Group)
Core Identities should probably be maintained by the centralized data council, offering an entity resolution service. Another advantage of using the RDF graph stack is that universal identifiers is part of the data model itself by using URIs.
The linkage between core business models and the applications models are source-to-target mappings which can be seen as transformations that can be represented in a declarative language like SQL and tools such as dbt. Another advantage of using RDF knowledge graphs is that you have standards to implement this: OWL to represent the business core models, R2RML to represent mappings from application database models to the business core models.
There are existing standard vocabularies such as W3C Data Catalog Vocabulary that can (and should) be used to represent metadata.
Data Mesh is about being resilient. Efficiency comes later. Actually, it won’t be efficient early on. It’s disruptive, due to many changes. This will probably be inefficient in the beginning. It will enable just a few teams and use-cases. But it will be the starting point of the data snowball.
The push needs to come from the top, executive level. This is aspirational. There is no ROI is not short term.
We need to encourage the bottom up. Data mesh is a way for each business unit to be autonomous and not be bottlenecked by IT.
The power of the data mesh is that everyone governs for their own use case, the important use cases get leveled up so it can be consumed by high level business use cases without over engineering.
A Catalog and Cocktails podcast episode on Data Mesh
Want to learn more about Data Mesh? Barr Moses wrote a Data Mesh 101 with pointers to many other articles. (Barr Moses will be a guest on Catalog and Cocktails in a few weeks!)
Every start of the year I like to reflect on the most memorable events of the previous year (this was 2019). It’s the start of 2021, and I ask myself, what was my most memorable event of 2020. Couldn’t come up with just one, so here are a few:
Honest, no-BS, non-salesy data podcast
Who would have thought that I would start a podcast! With my partner in crime, Tim Gasper, we host Catalog and Cocktails, an honest, no-bs, non-salesy podcast about enterprise data management. We record it live every Wednesday 4pm CT. We use the first 30 minutes of the show to record the podcast episode, and then open up the Zoom call right after for everyone to join in the discussion.
In 2021, our podcast is going to evolve and will have many guests to join the conversation. Listen to it on your favorite podcast app (Apple Podcast, Spotify), like and subscribe!
“Designing and Building Enterprise Knowledge Graphs” Book
Ora Lassila and I submitted a complete first draft of the book “Designing and Building Enterprise Knowledge Graphs” to the publisher on Dec 31!
I’ve been writing this book for a while now (longer than I want to admit). A silver lining of the pandemic is that I was able to focus more time on the book. Additionally, it was an honor that Ora joined me as a co-author. If you are interested in a sneak peak, let me know!
20+ talks
I value the opportunity to share my thoughts and ideas about data management with a wider audience. In 2020 I gave over 20 invited talks!
Back in October 2019, I gave a keynote at the Ontology Matching Workshop: The Socio-Technical Phenomena of Data Integration and Knowledge Graphs:
Data Integration has been an active area of computer science research for over two decades. A modern manifestation is as Knowledge Graphs which integrates not just data but also knowledge at scale. Tasks such as Domain modeling and Schema/Ontology Matching are fundamental in the data integration process. Research focus has been on studying the data integration phenomena from a technical point of view (algorithms and systems) with the ultimate goal of automating this task.
In the process of applying scientific results to real world enterprise data integration scenarios to design and build Knowledge Graphs, we have experienced numerous obstacles. In this talk, I will share insights about these obstacles. I will argue that we need to think outside of a technical box and further study the phenomena of data integration with a human-centric lens: from a socio-technical point of view.
The talk was very well accepted and I received numerous invitations to give it again:
At data.world I get to work on how to combine open and enterprise data catalogs. I was invited to give a talk on this topic titled, Open to an Enterprise Data Catalog and Back in the European Data Portal webinar series (video).
I also gave numerous invited talks to large companies and startups.
Final Thoughts
As expected I did not travel a lot in 2020 (my last trip was March 11). During the first months of 2020, I flew 37,000 miles and visited Canada, Belgium, Netherlands and India (in 2019 I flew 143,000 miles and visited 13 countries). Can’t wait to get back to travel in the second half of 2021 hopefully!
We all hated 2020 and can't wait for 2021 to start and let this pandemic be over.
Instead of complaining about 2021, I'm curious, what were your positives and silver linings of 2020?
I travelled a lot in 2019, actually a bit more than in 2018 but stayed more in Austin. I continue to be a United 1K, for my fourth consecutive year. I flew 143, 812 miles which is equivalent to 5.8 around the earth. I was on 101 flights and spent 350 hours (~14.6 days) on a plane. I visited 13 countries (including 3 new countries): Chile, Colombia, Cuba (new), Ecuador, France, Germany, Greece, Italy, Mexico, Netherlands, New Zealand (new), Paraguay (new) and Switzerland. I was on the road for a total of 142 days (~40% of the year) from which I spent 34 days in Europe, 28 days in Colombia, 18 days in Chile among others.
Given all this travel and everything I did in 2019 and everything that occurred throughout the year, I asked myself: what was my most memorable event of 2019?
In 2010s I spun off a company from my PhD and met a really awesome girl.
In 2019, I sold that company and married that girl.
My personal career aspiration is to have a cycle which starts from a basic research problem that is motivated by industry needs. However at the beginning of the cycle, the industry may not understand the importance and value of the basic research problem. Time goes by, the research matures and solutions are developed. Industry continues to evolve and eventually their problems and needs catch up to the solution that has been developed in the research. Time to commercialize! During commercialization is when you truly bridge research and industry; theory and practice (giving a talk on this topic was my most memorable event of 2018).
I started this cycle with the following basic research question: “How, and to what extent, can Relational Databases be integrated with the Semantic Web?” (see page 4 of my PhD dissertation). When I got exposed to the Semantic Web in mid 2000s, I always thought that companies would want to put “a semantic web” on top of their relational databases but they would not be able to move their data from their relational databases. Lo and behold, around 2010 we started to get knocks on our door asking about how to map relational databases to RDF graphs and OWL ontologies and that is how Capsenta started.
During commercialization, one of the many lessons I learned is that the business cares about the solutions to their problems and not necessarily the technology behind the solution. This is a mistake I see all the time: marketing and selling the technology instead of the solution. At Capsenta, we started to focus on the problem that business users are not able to answer their own questions in BI tools due to a conceptualization gap between business user’s mental model of the data and the actual physical representation of the data. We solved that problem using semantic web technologies.
With the acquisition of Capsenta by data.world, I feel that I have closed this first cycle. It took 10 years!
This cycle has been a tremendous learning experience for me. I will be writing a post about all the lessons learned through this cycle.
2020 will definitely bring a lot of exciting developments. Stay tuned!
Business users must answer business questions quickly to address Business Intelligence (BI) needs. The bottleneck is to understand the complex databases schemas. Only few people in the IT department truly understand them. A holy grail is to empower business users to ask and answer their own questions with minimal IT support. Semantic technologies, now dubbed as Knowledge Graphs, become useful here. Even though the research and industry community has provided evidence that semantic technologies works in the real world, our experience is that there continues to be a major challenge: the engineering of ontologies and mappings covering enterprise databases containing thousands of tables with tens of thousands of attributes. In this paper, we present a novel and unique pay-as-you-go methodology that addresses the aforementioned difficulties. We provide a case study with a large scale e-commerce company where Capsenta’s Ultrawrap has been deployed in production for over 3 years.
This is joint work with Will Briggs, Daniel Miranker and Wayne Heideman. This paper documents our experience and lessons learned, while at Capsenta, in order to design and build enterprise knowledge graphs from disparate and heterogeneous complex relational databases.
The Problem: how do we get non-semantic aware folks to design and build ontologies and subsequently create mappings from the complex schemas of enterprise database (1000s of tables and 10000s of attributes) to the ontologies.
Our answer: a methodology that combines ontologies and mappings, that is iterative, and focuses on answering business questions to avoid boiling the ocean.
It is great to see how we are applying this methodology with our customers at data.world.
Interested in learning more? Please read the paper! Still have questions? Reach out to me!
Finally, it is an amazing honor that this paper is nominated to best paper. We pride ourselves in striving for excellence.
I travelled a lot in 2018, but actually a bit less than 2017. I flew 132,064 miles which is equivalent to 5.3x around Earth. I was on 93 flights. I spent almost 329 hours (~14 days) on a plane. I visited 11 countries: Colombia, France, Germany, India, Italy, Japan, Mexico, Spain, South Korea, Turkey, UK. I was in Austin for 174 days (my home), 53 days in Europe, 31 days in Colombia and 14 days in Mexico, India and Japan.
Given all this travel and everything I did in 2018, I asked myself: what was my most memorable event of 2018?
Answer: The 14 times I gave my talk “Integrating Semantic Web in the Real World: A Journey between Two Cities” all around the world.
Abstract: An early vision in Computer Science has been to create intelligent systems capable of reasoning on large amounts of data. Today, this vision can be delivered by integrating Relational Databases with the Semantic Web using the W3C standards: a graph data model (RDF), ontology language (OWL), mapping language (R2RML) and query language (SPARQL). The research community has successfully been showing how intelligent systems can be created with Semantic Web technologies, dubbed now as Knowledge Graphs.
However, where is the mainstream industry adoption? What are the barriers to adoption? Are these engineering and social barriers or are they open scientific problems that need to be addressed?
This talk will chronicle our journey of deploying Semantic Web technologies with real world users to address Business Intelligence and Data Integration needs, describe technical and social obstacles that are present in large organizations, and scientific and engineering challenges that require attention.
It all started when Oscar Corcho invited me to be a keynote speaker at KCAP 2017. I wanted to give a talk that described the journey I’ve been going through with Capsenta which is commercializing the research that I did in my PhD and the lessons learned throughout the process. Apparently the talk was very well received and I quickly started to get invitations.
I deliver this talk wearing two hats: science and business. The goal of the talk is to provide an answer to the following question: Why is it so hard to deploy Semantic Web technologies in the real world?
I start by describing the research I did in my PhD and what was productized in Capsenta and continue to describe the status quo of data integration that we see in the real world. I share five observations that we have made when trying to use semantic web technologies to address data integration needs:
1. We are boiling the ocean because we want to create the ontology first.
2. Real world databases schemas are hard… really hard!
3. Real world mappings are hard… really hard!
4. Knowledge Hoarding
5. Tools are made for citizens of the Semantic City
I present ideas and solutions that we are working on at Capsenta to address these issues and bridge the chasm between the Semantic and Non-Semantic cities. Essentially, we need Knowledge Engineers, who need to be empowered with methodologies and tools. A final call to arms is made: we need to study the social-technical aspects of data integration.
A theme throughout the talk is that we need to know our history. Too much wheel reinventing is going on.
It has been a true honor to have the opportunity to give this talk so many times in 2018. I want to thank everybody who invited me, who listened to the talk, asked questions and fostered discussions. I’m extremely lucky to have had so many enlightening discussions which have sparked new research-industry collaborations. 2019 is going to be very exciting!
Without further adieu, here is a recording of the talk at KMI in Feb 2018
Okay, real talk time. I'm super burned out. Program chairing NeurIPS for two years in a row was brutal, especially when combined with family health issues and increased Microsoft obligations on top of my usual workload. My question for y'all: How do you deal with burnout? 1/3
and it got me thinking. I provided a short answer:
Replies are fantastic. My answer: – Keep a list of everything I need to do – Everyday focus on a couple of things from the list – Saturday is my day off – Exercise every day min 20 min. No excuse! – I enjoy cooking – Learn to say NO – Delegate – Dancing weekly – SLEEP 8 HOURS! https://t.co/oy9EsLxPBP
I kept reflecting on what I’ve been doing this year to avoid a burnout, so I decided to write this up.
Make Lists
Write down everything you need to get done. Just write it down. Doesn’t matter if it’s short, medium or long term. After that, you understand the lay of the land and you can start organizing and prioritizing. Every day I look at the list and ask myself “What do I need to cross off my list to consider that I had a successful day?”. I focus on those few issues. If you want to get more sophisticated, follow the Getting Things Done (GTD) time management method.
Learn to say No
One of the hardest things to do. This is something that everybody told me during grad school and everybody I talk to acknowledges that it’s a hard thing to do. Nevertheless, strive to say NO to more things.
Delegate
If you can, delegate. And when you do, then don’t worry about the task at hand. I know this is easier said than done and possible if you work in a team.
Read Magazine and Books. Watch documentaries
During grad school I always felt guilty if I was spending time reading non-research papers because I always had a large stack of paper to read. I still feel that guilt. However, I realized that by reading other material, I get a different perspective of the world and this helps in the diversity of ideas. If you ask around, highly successful people spend a lot of their time reading, even with their hectic schedule.
I go dancing and try to go once a week at least. Cooking is my relaxation. I also avoid working on Saturday.
Just Relax!
Sometimes I feel like I didn’t accomplish anything during the day and I feel guilty. It’s fine if I don’t feel productive. Just relax. I know that I will probably have another moment where I will be extremely productive.
Be Healthy
Last but not least, focusing on my health has been game changer. This involves going to the gym and eating healthy. I’ve never been a gym-going person. However I did find an amazing gym, Dane’s Body Shop, which is community oriented. When I’m in Austin, I look forward to going to the gym everyday!
I also started working with Veronica Bumpass, the nutritionist at the gym to support and guide me on organizing a healthy lifestyle, specially when I travel. I’m very conscience of what I eat, workouts I can do when I travel, all while still enjoying the fun lifestyle that I like to have.
A couple of tips:
1) work out 20 mins every day. No excuses. You can find plenty of workouts that you can do at home with no equipment. Just make sure that you have a correct form and for that, start working out with a trainer.
2) SLEEP 8 HOURS! No excuses.
3) When you are eating, ask your self “are those calories worth it?”
4) Do you have to be on the phone? Take a walk while you are on the call.
If you learn to say NO, and delegate other tasks, you will have more time. Having a healthy lifestyle will make you feel stronger, physically and mentally. Give your brain a break by relaxing, having fun, reading, etc. Everyday focus on a the top priority things on your list.
Finally, by coincidence, I saw this today:
How do you get the good night's sleep when you're full of stress and anxiety?
Scientist investigate to understand natural phenomena, find answers to unsolved questions, in order to ultimately expand the knowledge of mankind. Yes this sounds cliche, but it’s true.
We should remember that science is a social process. It is paramount for scientist to be social and communicate with peers in order to share their ideas, hypothesis, results and receive critical feedback from others. This communication, historically and still today, is done written (papers) and orally (talks and conversations at conferences).
I can only provide my opinion from a computer science point of view, and my impression is that there is a tremendous focus today on reviewing, publications, conferences and citation counts.
I think we are forgetting the big picture: reviewing, publications, conferences are a means to an end. It is the means of communicating in order to achieve the end of understanding something that we do not understand today.
Some ideas/comments (inspired after a conversation with Wolfgang Lehner when I visited TU Dresden and talking to other colleagues in different sciences)
Papers published in top tier conference proceedings have a lot of weight in Computer Science. Fellow colleagues in other scientific fields find it amusing when we get excited about a conference publication because in most (all?) areas of science, journal papers are what counts. I know that the excuse is that CS moves so quickly and journal reviews take too long. So this is what we have to change. Therefore …
Conference submissions should be extended abstracts. Reviewing for these extended abstracts should be light. That means that we have less work as reviewers.
All accepted abstracts are presented as posters. The goal is to foster discussion, right?!We should have longer poster sessions everyday so everybody can have a chance to present and also see what others are doing. For example, recently, I received an email from a colleague who sent me a draft paper which was partly inspired by our discussion that we had in SIGMOD 2017. I didn’t even have a poster at the conference, it was just a conversation we had on our way to the gala dinner. We need to have more outlets for these types of conversations.
Journal papers get invited for longer presentations. ISWC and WWW (now TheWebConf) has been doing this for a couple of years now (and I’m sure other conferences too). All conferences should be doing this!
During the conference presentations, we should spend more time on discussion in addition to giving just talks, and having the session chair asking a question at the end because everybody is looking at their laptop. One idea is to create panels by grouping scientists who are working on the same topic. This is common in social science conferences.
We should publish in venues that don’t limit you on a fixed page limit (i.e. journals). Have something to say. Say it. Finish when you are done saying it (and give it a good title… this is advice that I heard from Manuela Veloso.)
– Research on a deadline is either engineering or not really research. Therefore, we should not focus on fixed yearly deadlines; you should be able to submit whenever you want. Submit when your work is actually DONE! Not when the conference deadline tells you. That way you can stop running experiments last minute (btw if you do that, your research is not done and not ready to be shared, IMO). I think the PVLDB model is fantastic and should be widely adopted in CS. I know that the typical excuse is that we need deadlines. BS! If you can’t manage your own time, then you have a bigger problem.
If conferences submissions are just extended abstracts, then we can focus our reviewing efforts on substantial papers.
At AMW2018, Paolo Guagliardo presented somebody else’s paper. He read the paper and did the best presentation possible which I’m sure will become a memorable presentation. Talking later to Hung Ngo and Paolo, we thought that it would be incredibly interesting to have a fellow colleague present your work. This could either be a PC member who reviewed your paper, or another colleague who shares the same interest and is willing to read the paper and present it. Imagine having somebody else being critical about your paper and present it to others. A bit risky for sure, but why not try this out with people who are willing to swap. Maybe at your next conference, you can surprise the audience with this approach. I know I would love to do it.
I acknowledge that my suggestion will never work due to the larger “system”. CS academics get evaluated by universities and funding agencies through the quantity of publications and citation counts. That has to be reformed. Easier said than done of course. If that continues to be the norm of evaluation, we are going to stay in the same place and keep adding bandaid after bandaid and hearing the same rants without any progressive change. Scientist high up in the ranks who have power are the ones that can make the change. I truly believe we need a change.
I recently attend the 1st US Semantics Technology Symposium. I quickly published my trip report because I wanted to get it out asap, otherwise I would never get it out (procrastination!). It’s been a week since my trip report and I can’t stop thinking about this event. After a week of reflection, I realized that there is a big picture that did not come across my trip report: THE US2TS WAS A VERY BIG DEAL!
Why? Three reasons:
1) There is a thriving U.S. community interested in semantic technologies
2) We are not alone! We have support!
3) Time is right for semantic technologies
Let me drill through each one these points.
1) There is a thriving US community interested in semantic technologies
Before the event, I asked myself: what does success look like personally and for the wider community after this event? I didn’t know what to expect and honestly, I had low expectations. I was treating this event as a social gathering with friends and colleagues that I hadn’t seen in a while.
It was much more than a social gathering. I realized that there was a thriving US community interested in semantic technologies, outside of the usual suspects (academics such as USC/ISI, Stanford, RPI, Wright State, UCSB and industry such as IBM and Franz). At the first coffee break, I told Pascal “I didn’t know there were all these peoples in the US interested in semantic technologies!”. Apparently many people shared the same comment with Pascal. US2TS was the first step, in my opinion, to unify an existing community that was not connected in the US.
I’ve known about the semantic work that Inovex and GE Research have been doing. I was very glad to see them coming to an event like this and publicizing to the wider community about what they are doing.
Very exciting to meet new people and see what they are doing coming from places such as Maine, U Idaho, UNC, Cornell, UC Davis, Pitt, Duke, UGA, UTEP, Oregon, Bosch, NIST, US AF, USGS, Independent Consultants,
Additionally, very exciting to see the different applications domains. Life Science has always been prominent. I learned about the complexity of geospatial and humanities data. I’m sure there are many more similar complex use cases out there.
2) We are not alone! We have support!
The US government has been funding work in semantic technologies through different agencies such NSF, DARPA and NIH. Chaitan Baru, Senior Advisor for Data Science at the National Science Foundation had a clear message. NSF thinks of semantic technologies as a central component of one of its Ten Big Ideas: Harnessing the Data Revolution:
How do we harness the data revolution? Chaitan and others have been working through NITRD to promote an Open Knowledge Network that will be built by many contributors and offer content and services for the research community and for industry. I am convinced that an Open Knowledge Network is key component to harness the data revolution! (More on Open Knowledge Network below.)
Basically, NSF is dangling a $60 million carrot in front of the entire US Semantic Technologies community.
Chaitan’s slides will be made available soon through the US2TS web site.
3) Time is right for Semantic Technologies
Semantic Technologies work! They solve problems that require integrating data from heterogeneous sources where having a clear understanding of the meaning of the data is crucial. Craig Knoblock’s keynote described how to create semantic driven applications from end to end in different application domains. Semantic technologies are key to address these problems.
One of the themes was that we need better tools. Existing tools are made for citizens of the semantic city. Nevertheless, we know that the technology works. I argue that it is the right opportunity to learn from our experiences and improve our toolkits. There may not be science in this effort and that’s fine. I think that is a perfect fit for industry and startups. I really enjoyed talking to Varish and learning how he is pushing for GE Research to open source and disseminate the tools they are creating. Same for Inovex. One of our goals at Capsenta is to bridge the chasm between the semantic and non-semantic cities by creating tools and methodologies. Tools don’t have to come just from academia. It’s clear to me that the time is right industry to work on tools.
1) The thirst for semantics are growing: We are seeing the interest in other areas of Computer Science, namely, Machine Learning/Data Science (slide 3), Natural Language Processing (slide 4), Image Processing (slide 5), Big Data (slide 6) and Industry through Knowledge Graphs (slide 7). If the thirst for semantics is growing, the question is, how are we quenching that thirst? We are seeing Deep Learning workshops at semantic web conferences. It’s time that we do it the other way: semantic/knowledge graphs papers and workshops at Deep Learning conferences.
2) Supercomputing analogy: In 1982, Peter Lax chaired a report on “Large Scale Computing in Science and Engineering”. During that time, supercomputing had major investments by other countries, dominated by large industry players, limited access to academia and lack of training. The report recommend NSF to invest in Supercomputing. The result was the National Science Foundation Network (NSFNET) and the Supercomputing centers that exist today. This seems like an analogous situation when it comes to semantics and knowledge graphs: major investments by other countries (Europe), dominated by large industry players (Google, etc), limited access to academia (not mainstream in other areas of CS) and lack of training (we need to improve the tools). I found this analogy brilliant!
3) We need an Open Knowledge Network: As you can imagine, to continue the analogy, we need to create a data and engineering infrastructure around knowledge, similar to the Supercomputing centers. An Open Knowledge Network would be supported by centers at universities, support research and content creation by the broader community, be always accessible and reliable to academia, industry, and anyone, and enable new scientific discoveries and new commercial applications. For this, we need to think of semantic/knowledge graphs as reliable infrastructure, train the next generation of researchers, and think of the Open Knowledge Network as a valuable resource worth of collective investment.
Do yourself a favor and take a look at the Yolanda’s slides.
Conclusion
This is perfect timing. We have a thriving semantics technology community in the US. Semantic technologies work: we are seeing a thirst for semantics and interest from different areas of computer science. Finally, the NSF has a budget and is eager to support the US Semantic technologies community.