I had the honor to moderate the Data Architecture panel at the 2021 Knowledge Graph Conference. The panelist were:
– Zhamak Dehghani, Director of Emerging Technologies at ThoughtWorks and the founder of Data Mesh concept
– Teresa Tung, Chief Technologist of Accenture’s Cloud First group
– Jay Yu, Distinguished Architect and Director, Enterprise Architecture and Technology Futures Group at Intuit
This panel was special edition of the Catalog and Cocktails podcast that I host, an honest, no-bs, non-salesy conversation about enterprise data management. We will be releasing the panel as a podcast episode soon, so stay tuned!
In the meantime, these are my takeaways from the panel:
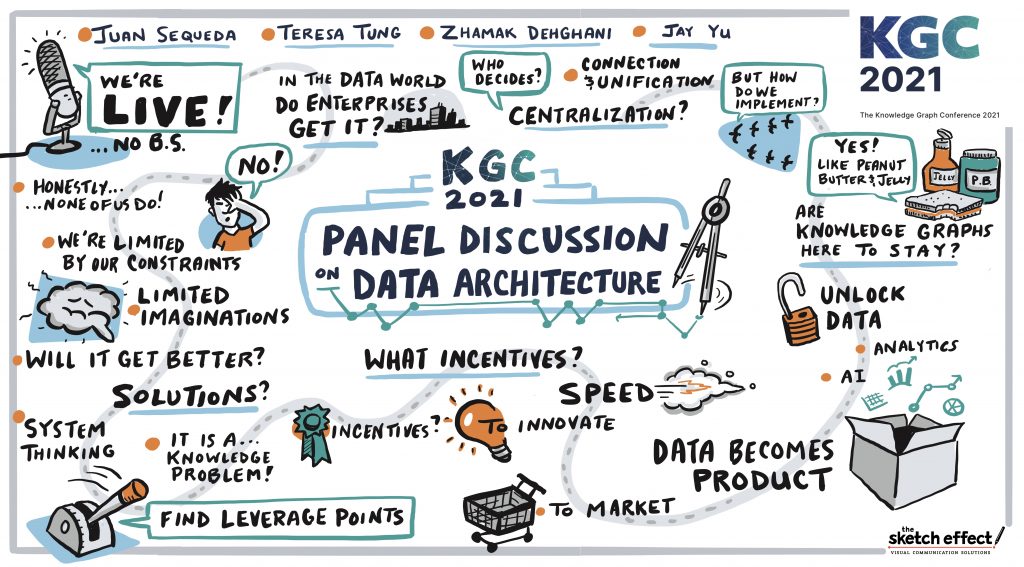
What are the incentives?
– Need to understand the incentives for every business unit.
– Consider the common good of the whole, instead of individualism
– Example of incentive: put OKRs and bonus on the shareability and growth of the users of your data products
Knowledge Graph and Data Mesh
– Knowledge Graph is an evolution of master data management.
– Data Mesh is an evolution of data lake.
– Knowledge Graph and Data Mesh complement each other. They need to go together.
– However, we still need to figure out how to put them together.
Centralization vs Decentralization
This was the controversial part of the discussion.
– Jay’s position is that the ultimate goal is to unified data and decentralized ownership of domain is a step in that direction. Zhamak and Teresa do not fully agree.
– Intuit’s approach: There are things that should be fix (can’t change, i.e. address), flexible (ability to extend) and customize (if you need to hit the ground running)
– Is the goal to unify data or have unifiable data?
– Centralization and Decentralization: sides of the same coin
– Centralize within a same line of business that is trying to solve the same problem. But can’t expect to follow all the new demands of data in the world.
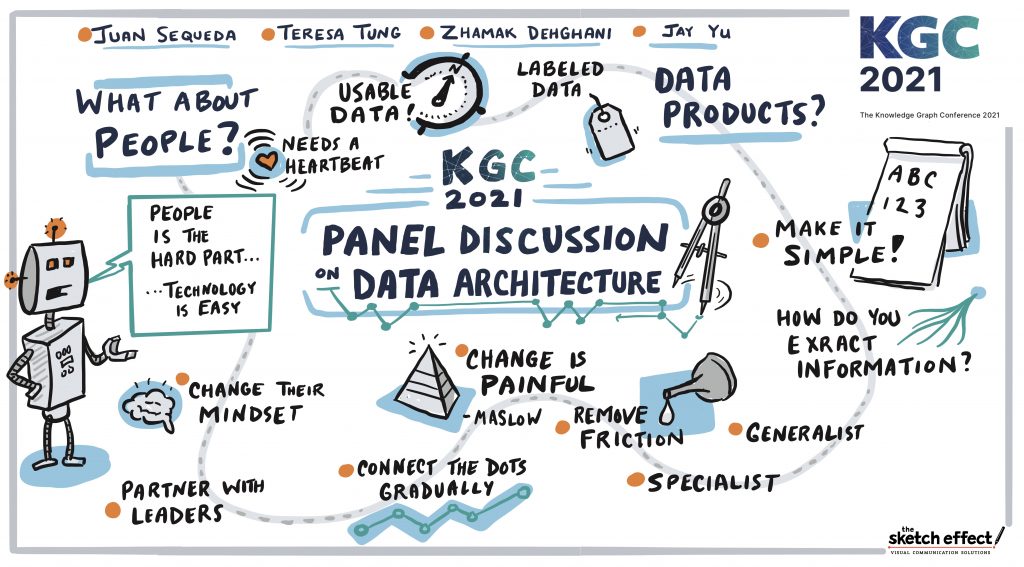
People
– Need to have an answer to “what’s in for me?” question. See incentives takeaway.
– Consider Maslow’s hierarchy of needs
– Be bold, challenge the status quo
– Follow the playbook on change management
Honest, no-bs: What is a Data Product?
– Native data products which are close to the raw data. Intelligent data products which are derived from the native data products
– A data product is complete, clean, documented, with knowledge about the data, explanation on how people can use it, understand the freshness, lineage, useful
– If you find something wrong with the data product, you need to have ways of providing feedback.
– Data Products needs to have usability characteristics.
– Data has a Heartbeat: it needs to be alive. The code keeps the data alive. Code and data need to be together. Otherwise it’s like the body separated from the soul. (Beautifully said Zhamak!)