ISWC has been my go-to conference every year. This time it was very special for two reasons. First of all, it was my 10 year anniversary of attending ISWC (first one was ISWC2008 in Karlsruhe where I presented a poster that ultimately became the basis of my PhD research and also the foundational software of Capsenta). Too bad my dear friend and partner in crime, Olaf Hartig, missed out (but for good reasons!). I only missed ISWC2010 in Shanghai; other than that, I’ve attended each one and I plan to continue attending them (New Zealand next year!)
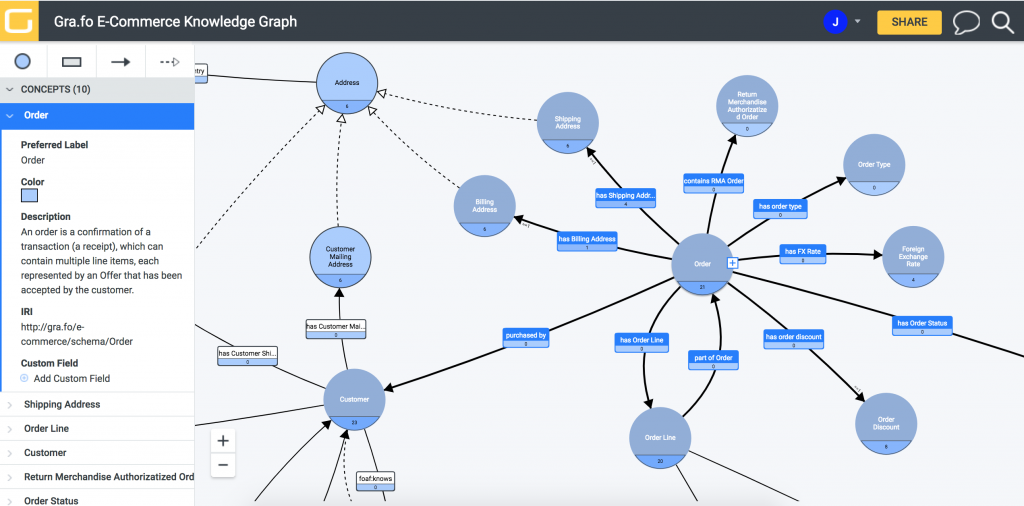
The other reason why this was a special ISWC is because we officially launched Gra.fo, a visual, collaborative, real-time ontology and knowledge graph schema editor, which we have been working on for over 2 years in stealth mode.
Extremely excited to share with everybody what @Capsenta has been working on for the last two years in stealth mode: https://t.co/XXFqdJgxAR, a visual, collaborative, real-time ontology and knowledge graph schema editor #Grafo #KnowledgeGraph https://t.co/wpFbmsYYDr pic.twitter.com/YxUi5GaGDo
— Juan Sequeda (@juansequeda) October 19, 2018
@heikopaulheim and @juansequeda opening #THEworkshop @iswc2018 #ISWC2018 @lysander07 pic.twitter.com/6tzHf7R4eY
— Maria Koutraki (@mairyl0u) October 8, 2018
Intense discussion going on at THE workshop at #iswc2018 – it's been a great pleasure to see so many ideas. pic.twitter.com/srWxBTIY2v
— Heiko Paulheim (@heikopaulheim) October 8, 2018
And that’s a wrap for the first THE Workshop, an unconventional workshop where we discussed open problems and actually had to work! Great discussions, ~30 ppl (30% women, the diversity of this community is fantastic!). The submissions will be published soon online #iswc2018 pic.twitter.com/YWed8pZDI2
— Juan Sequeda (@juansequeda) October 8, 2018
VOILA: I’ve been attending the Visualization and Interaction for Ontologies and Linked Data (VOILA) Workshop for the past couple of years (guess why 🙂 ) and luckily I was able to catch the last part of it. My take away is that there is a lot of cool things going on in this area but the research problems that are being addressed are not always clear. Furthermore, prototypes are engineered and evaluated but it’s not clear who is this tool for. Who is your user? I brought this up in my trip report from last year. This community MUST partner with other researchers in HCI and Social Science in order to harden the scientific rigor. Additionally, there are cool ideas that would be interesting to see if there is commercial viability.
SHACL: I attended the Validating RDF data tutorial by Jose Emilio Labra Gayo. I came in trying to find an answer to the following question: Is SHACL ready for industry prime time? The answer is complicated but unfortunately I have to say, not yet. First of all, even though SHACL is the W3C recommendation, there is another proposal called ShEx from Jose Emilio’s group. He acknowledges his bias but if you look at the ShEx and SHACL side by side, you can argue for one or the other objectively. For example, ShEx supports recursive constraints, but SHACL doesn’t (There was a research paper on this topic, Semantics and Validation of Recursive SHACL, … but it’s research!). Nevertheless, the current SHACL specification is stable and technically ready to be used in prime time. The problem is the lack of commercial tools for enterprise data. Jose Emilio is keeping a list of SHACL/ShEx implementations but all except for TopQuadrant, are (academic) prototypes. Seems like Stardog is planning to officially support it in their 6.0 release. At this stage, I was expecting to see a standalone SHACL validator that can take as input RDF data or a SPARQL endpoint and run the validations. With all due respect, but these kind of situations are embarrassing for this community and industry: apparently a standard is needed, a recommendation is made, but at the end there is no industry implementation and uptake (one or two is not enough). We live in a “build it and they will come” world and this does not make us look good. </rant>. On a positive note, I think we are very close to the following: create a SHACL to SPARQL translator that starts out by supporting a simple profile of SHACL (cardinality constraints). This way anybody can use this on any RDF graph database. Somebody should build this, and we should support it as a community, not just academics but also having industry users behind it.
Hat tip to Jose Emilio for the nice SHACL/ShEx Playground and to Eric, Iovka and Dimitris for making their book, Validating RDF, available for free (html version).
Knowledge Graph challenges from Yuqing Gao (Microsoft) #iswc2018 #iswc_conf pic.twitter.com/oNeOOKN9Ro
— Juan Sequeda (@juansequeda) October 11, 2018
Facebook Knowledge Graph is just starting. Even the stickers are annotated!! #iswc2018 #iswc_conf pic.twitter.com/KfLEUPmy0r
— Juan Sequeda (@juansequeda) October 11, 2018
Alan Patterson (EBay). They’ve been working on their Knowledge Graph for under a year. Biggest problem is identity (record linkage), depending on context. #iswc2018 #iswc_conf pic.twitter.com/yhfvV1de0V
— Juan Sequeda (@juansequeda) October 11, 2018
Jamie Taylor (Google). KG has 1 billion things, 70 billion facts. Not enough. Challenges: managing identity (Chicago Bull w MJ and w/o MJ are the same?) managing semantic stability (I.e. the meaning of sports has evolved) #iswc2018 #iswc_conf pic.twitter.com/2PrRgssZkW
— Juan Sequeda (@juansequeda) October 11, 2018
Anshu Jain (IBM): Knowledge Graphs are about discovery. Also, you need a polymorphic store (you can’t do everything with one type of technology). Challenges: modeling change, this isn’t being worked on. #iswc2018 #iswc_conf pic.twitter.com/LTmCy7P8U4
— Juan Sequeda (@juansequeda) October 11, 2018
KG Panel: Large scale graph management is more than just having a graph database. Currently setup is mix of a lot of technologies. A lot of systems challenges i.e Need streaming of graphs combined with Kafka, etc. cc @vj_chidambaram #iswc2018 #iswc_conf
— Juan Sequeda (@juansequeda) October 11, 2018
Reasoning in Knowledge Graphs? For type checking. To recommend places (if it has quiet music then probably a good place to work). Proprietary reasoning systems #iswc2018 #iswc_conf
— Juan Sequeda (@juansequeda) October 11, 2018
Question from Yolanda Gil: we have Apache Software Foundation and software like Tomcat that everybody uses. Where is the Comanche Knowledge Foundation and software that can be reused by the community? Applause from the room. Answer: mmmm wikidata, schemaorg#iswc2018 #iswc_conf
— Juan Sequeda (@juansequeda) October 11, 2018
Challenges for the scientific community: privacy, federation over multiple graphs that return different types of answers, can we scan the news every day and learn new facts with high precision, combining KG and ML, make sure that KR is part of the curriculum#iswc2018 #iswc_conf
— Juan Sequeda (@juansequeda) October 11, 2018
Not everybody is a Google: The challenges stated by the Enterprise Knowledge Graph panelist are for the Googles of the world. Not everybody is a Google. For a while now, I feel that a large research focus is on tackling problems for the Googles of the world. But what about the other spectrum? My company Capsenta is building knowledge graphs for very large companies and I can tell you that building a beautiful, clean knowledge graph from even a single structured data source, let alone a dozen, is not easy. I believe that the semantic web, and even the database community have forgotten about this problem and dismissed this as day to day engineering challenges. The talk “Integrating Semantic Web in the Real World: A Journey between Two Cities” that I have been giving this year details all the open engineering, scientific and social challenges we are encountering. One of those problems is defining mappings from source to target schemas. Even though the Ontology Matching workshop and the Ontology Alignment Evaluation Initiative have been going on for over a decade… the research results and systems do not address the real world problems that we see at Capsenta in our day to day. We need to research the real world social-technical phenomenons of data integration. One example is dealing with complex mappings. I was very excited to see the work of Wright State University and their best resource paper nominated work “A Complex Alignment Benchmark: GeoLink Dataset”. This is off to a good start but there is still a lot of work to be done. Definitely a couple of PhDs can come out of this.
Natasha Noy’s keynote: I really enjoyed her keynote, which I summarized:
Very nice keynote by N. Noy
My takeaways:
-science vs engineering, is about the hypothesis “build it & they will come”
-dataset search: we can ask new research questions,
-science is a social process, we need to talk to others and solve REAL problems! #iswc2018 #iswc_conf pic.twitter.com/olyvqqSNRy— Juan Sequeda (@juansequeda) October 11, 2018
Google Dataset Search #iswc2018 #iswc_conf pic.twitter.com/4uPFwUbe4Y
— Juan Sequeda (@juansequeda) October 11, 2018
Keynote by Vanessa Evers (@evers_vanessa) brought a great light on how semantics and reasoning help to make socially intelligent robots. Fantastic and funny examples!!! #iswc2018 #iswc_conf pic.twitter.com/9VvQtWS7vP
— Juan Sequeda (@juansequeda) October 12, 2018
Industry: I was happily surprised to see a lot of industry folks this year. The session I chaired had about 100 people.
Standing room in the industry track of #iswc2018 #iswc_conf. Fantastic to see how Semantic Web and Knowledge Graphs are being used in the real world. It’s not just an academic exercise anymore pic.twitter.com/K0PLbVMjDg
— Juan Sequeda (@juansequeda) October 10, 2018
Super excited! Our work on explaining knowledge graph relationships has been judged as the best paper at @iswc2018.
Thanks to the reviewers who gave extremely valuable suggestions to improve our work. #iswc_conf https://t.co/lNMOdsIQFi#ibm @IBMResearch— Sumit Bhatia (@sbhatia_) October 12, 2018
The Chilean mafia at it again: Best Student Research paper @IMFDChile #iswc2018 #iswc_conf pic.twitter.com/CElovC6XF5
— Juan Sequeda (@juansequeda) October 12, 2018
Best Resource Paper #iswc2018 #iswc_conf pic.twitter.com/uYB7dsoJMJ
— Juan Sequeda (@juansequeda) October 12, 2018
Best In-use Paper to @wikidata #iswc2018 #iswc_conf pic.twitter.com/2137cG5dbe
— Juan Sequeda (@juansequeda) October 12, 2018
Best Poster and Best Demo Award #iswc2018 #iswc_conf pic.twitter.com/ym8yIn1FNd
— Juan Sequeda (@juansequeda) October 12, 2018
DL: Seems like DL this year meant Deep Learning and not Description Logic. I don’t think there was any paper on Description Logic, a big switch from past years.
Students and Mentoring: I enjoyed hanging out with PhD students and offering advice at the career panel during the Doctoral Consortium and at the mentoring lunch.
Ending this year's #iswc2018 DC with a career panel with @esimperl @juansequeda @vrandezo Tania Tudorache @iswc2018 pic.twitter.com/DzcnEBYKJB
— Sabrina Kirrane (@SabrinaKirrane) October 9, 2018
Science is a social process… you got to talk with people..
Nice discussion at the mentoring lunch with @juansequeda and @fabien_gandon #iswc2018 #iswc_conf
— Angelo A. Salatino (@angelosalatino) October 10, 2018
Striving for Gender Equality: I am extremely proud of the semantic web research community because they are an example of always striving for gender equality. This year they had a powerful statement: conference was organized entirely by women (plus Denny and Rafael) and they had 3 amazing women keynotes. Additionally, the local organizers did a tremendous job!
Furthermore, Ada Lovelace Day, which is held every year on the second Tuesday of October, occurred during ISWC. So what did the organizers do? They held the Ada Lovelace celebration where we had a fantastic panel discussing efforts on striving for gender equality in the sciences (check out sciencestories.io!)
Our #AdaLovelaceDay celebration. I am really overwhelmed with the great attendance. Thanks #iswc2018 pic.twitter.com/FP7xWLY3x8
— Anna Lisa Gentile (@AnLiGentile) October 10, 2018
What an awesome research community: I am very lucky to consider the Semantic Web community my research home. It’s a work hard, play hard community.
Asilomar, not a bad place to have a conference #iswc2018 pic.twitter.com/NKeYEigw2A
— Juan Sequeda (@juansequeda) October 8, 2018
What do you do at the end of your day at a Confernece? We sing with @heikopaulheim #iswc2018 pic.twitter.com/y6RE6E1Z66
— Juan Sequeda (@juansequeda) October 9, 2018
The #iswc2018 #iswc_conf dinner and party at the Monterey Aquarium was simply amazing!!! I say this again and again: this is a fantastic research community! pic.twitter.com/xxAGSXxfOq
— Juan Sequeda (@juansequeda) October 11, 2018
Looking forward to hit the stage with my fellow researchers! This only happens at #iswc_conf pic.twitter.com/1ChSSjiKiq
— Heiko Paulheim (@heikopaulheim) October 12, 2018
The epic #iswc2018 #iswc_conf Jam Session. We are not just computer scientists working on Semantic Web and Knowledge Graphs. We are also musicians and dancers, and we know how to have fun and throw a party!! pic.twitter.com/BvM0Cafn9i
— Juan Sequeda (@juansequeda) October 12, 2018
ISWC Jam Session
Posted by Juan Sequeda on Thursday, October 11, 2018
Posted by Juan Sequeda on Thursday, October 11, 2018
Posted by Juan Sequeda on Thursday, October 11, 2018
See you all next year in Auckland for ISWC 2019! #iswc_conf pic.twitter.com/5D3C2DkzzA
— Juan Sequeda (@juansequeda) October 12, 2018